3D Object Tracking - Experiments
In this post, we delve into the world of 3D object tracking, starting with its definition and why it’s important. We’ll then explore the key evaluation metrics used to assess tracking algorithms effectively. Next, we’ll take a closer look at cutting-edge algorithms that rely solely on point clouds as input data, utilizing the bird’s-eye-view (BEV) representation. Moving forward, we’ll discuss our ongoing experiments, providing insights about our findings. Finally, we’ll discuss what are our next steps.
Definition of 3D object tracking
The primary distinction between object detection and object tracking is that object detection involves both localization and classification, while object tracking focuses on the trajectory of the target movement in addition to localization based on object detection. The classification referred to mainly pertains to target types such as cars, pedestrians, and bicycles. Undoubtedly, the vehicle category is of utmost importance. Many comprehensive reviews on 3D object detection present detailed experimental results specifically for this category [1].
Object tracking involves establishing the position relationship of the object being tracked in a continuous video sequence or point cloud sweeps, obtaining its complete motion trajectory. During this tracking process, several challenges may arise, including changes in shape and lighting, variations in target scale, target occlusion, target deformation, motion blur, fast target motion, target rotation, target escape from parallax, background clutter, low resolution, and other phenomena.
The differentiation between 2D and 3D object tracking lies in the dimensionality of the space in which the tracking occurs. While 2D multi-object tracking (MOT) operates within a two-dimensional plane, primarily capturing object movement along the x and y axes, 3D MOT expands into the third dimension, incorporating depth information along the z-axis. This distinction profoundly impacts the complexity and scope of tracking tasks.
2D MOT typically relies on image-based data, such as frames from a single camera feed, where objects are represented as bounding boxes. Tracking algorithms in this domain focus on estimating object trajectories within the camera’s field of view, dealing with challenges like occlusions, changes in appearance, and object interactions. However, without depth information, 2D MOT struggles to accurately capture object movements in scenarios where depth plays a crucial role, such as distinguishing between objects at different distances or handling occlusions in a multi-layered environment. On the other hand, 3D MOT operates in a volumetric space, leveraging depth data provided by sensors like Lidar or stereo cameras. By incorporating depth information, 3D MOT algorithms can discern objects’ spatial relationships more accurately, enabling robust tracking in complex scenarios.
Evaluation metrics
In traditional 2D MOT, performance evaluation revolves around two pivotal metrics: Multiple Object Tracking Accuracy (MOTA) and Multiple Object Tracking Precision (MOTP). MOTA serves as a yardstick for the accuracy of the tracking system, while MOTP gauges precision, reflecting the proximity of obtained values to the true values. High scores in both MOTA and MOTP signify superior tracking performance, making them essential benchmarks for assessing tracking systems.
However, in the realm of 3D multi-object tracking, a shift towards more comprehensive evaluation metrics is observed, with special emphasis on two metrics: Averaged Multi-Object Tracking Accuracy (AMOTA), Averaged Multi-Object Tracking Precision (AMOTP).
One notable challenge in traditional evaluation methodologies is the reliance on a single confidence threshold, which may not fully capture the system’s accuracy spectrum. This limitation can obscure the true performance of MOT systems, as a high MOTA at one threshold may not translate to consistent performance across various operating points. To address this, there’s a growing consensus on the importance of understanding performance across multiple thresholds.
To mitigate this limitation, integral metrics like AMOTA and AMOTP have been proposed [2]. These metrics synthesize MOTA and MOTP values across various thresholds, providing a more comprehensive assessment of tracking performance. Specifically, AMOTA and AMOTP are computed by integrating MOTA and MOTP values over all recall values, such as the area under the MOTA over recall curve.
By adopting such holistic evaluation frameworks, researchers aim to develop more robust and adaptable MOT systems capable of maintaining high performance across diverse operating conditions.
State of the art
3D multi-object tracking (MOT) encompasses diverse approaches, each leveraging different data modalities. These modalities include camera-based, point cloud-based, and multi-modality-based methods. Furthermore, within the realm of 3D MOT, methods can generally be categorized into two main groups: model-based methods and deep learning based methods. These categorizations provide a framework for understanding the diverse methodologies employed in tackling the challenges of 3D MOT, each with its unique strengths and applications. Figure 1 shows the chronological overview of 3D MOT.
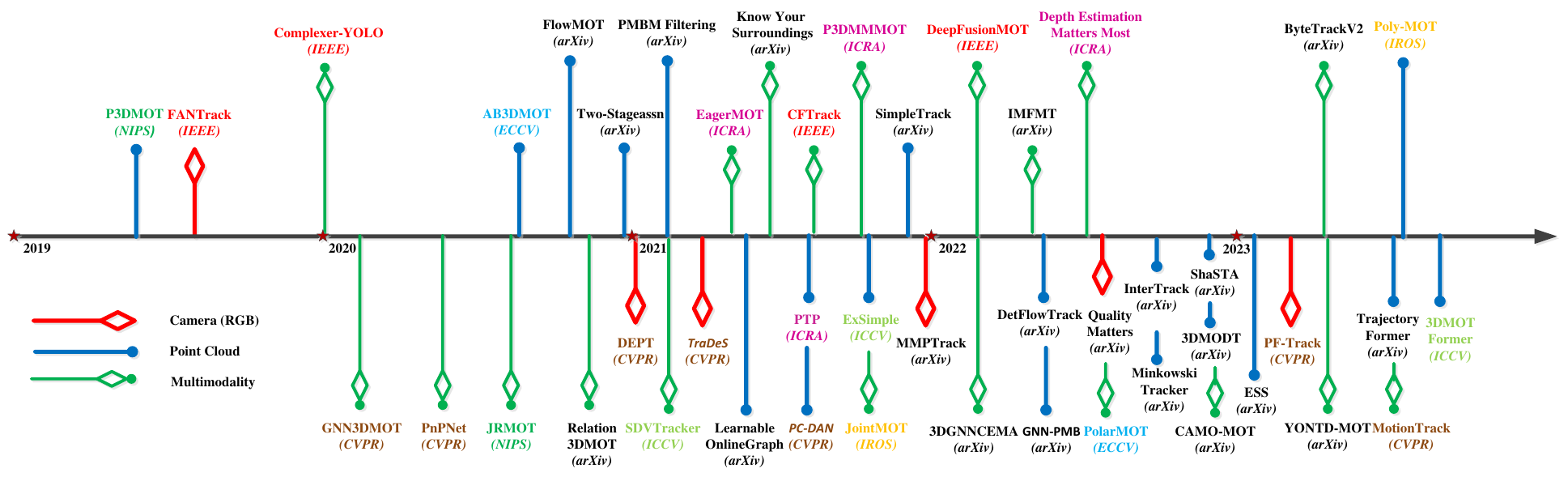 Figure 1: A chronological overview of 3D multi-object tracking methods [1]. Model-based approaches above the timeline and deep learning based approaches below the timeline.
Figure 1: A chronological overview of 3D multi-object tracking methods [1]. Model-based approaches above the timeline and deep learning based approaches below the timeline.
In the realm of point cloud-based 3D MOT, the model-based methods constitutes a prominent framework, comprising four main modules: object detection, motion prediction, association matching, and trajectory management. Prediction methods, such as the Kalman filter (KF) and the Constant Velocity (CV) prediction model, play crucial roles in forecasting object movements. While the KF prioritizes smooth predictions, the CV model excels in handling sudden and unpredictable movements. Association modules commonly employ IOU-based or distance-based techniques, with matching algorithms exploring the problem as a bipartite graph matching using the Hungarian algorithm or using greedy algorithms. The advantage of correlation filtering lies in its computational efficiency and simplicity. However, its reliance on recent frame information poses challenges, particularly in scenarios with inaccurate localization or occlusions, where tracking failure may occur due to model contamination.
In contrast, deep learning-based approaches in 3D MOT offer enhanced adaptability and accuracy. Architectures such as LSTM, MLP, CNN, RNN, GNN, and Transformer exhibit varying strengths, with LSTM and GNN currently dominating applications. Notably, research is shifting towards transitioning from 2D and 3D single-object tracking to 3D MOT using transformer architectures, reflecting the evolving landscape of deep learning in tracking methodologies.The deep learning framework for 3D MOT encompasses five key stages, similarly to the model-based methods: object detection, motion prediction, affinity calculation, association, and life cycle management. Compared to traditional methods, the deep learning based algorithms can better adapt to environmental changes, enhancing tracking accuracy and speed.
Our discussion and experiments will exclusively center on deep learning based methods using point clouds as input data. This decision aligns with the initial focus of our PhD project, which concentrates solely on utilizing point cloud input data and deep learning based methods, particularly leveraging the Bird’s Eye View (BEV) representation. By narrowing our focus to this specific approach, we can delve deeply into the intricacies and optimizations relevant to our research objectives.
Deep learning methods for point clouds as a single data input source emerged relatively recently, with notable advancements in the field. Among these, PTP [3], published in April 2021, introduced innovations building upon the AB3DMOT baseline model. PTP integrated neural learning networks, employing a two-layer LSTM and MLP for motion feature acquisition, alongside two layers of GNNs for feature aggregation. This enhanced feature extraction facilitated more accurate data association tasks. Similarly, Learnable Online Graph Representations [4], also published in the same month, proposed a graph structure for joint detection and tracking states processing, employing a fully trainable neural message-passing network for data association. These approaches demonstrated improved track stability and achieved promising results in benchmark datasets. The authors of [5] addressed the heuristic matching challenges in tracking-by-detection approaches, presenting the SimTrack method as a simplified and accurate end-to-end 3D multi-object tracking paradigm.
In 2022, DetFlowTrack [6] proposed a framework for simultaneous optimization of object detection and scene flow estimation in 3D MOT, achieving competitive results, particularly in scenarios with extreme motion and rotation. GNN-PMB [7] introduced an RFS-based tracker for online Lidar MOT tasks, demonstrating simplicity and competitive performance on benchmark datasets.
InterTrack [8] introduced an interactive transformer for 3D MOT, producing discriminative object representations for data association and achieving significant improvements, particularly in small target object aggregation. Minkowski Tracker [9] aimed to jointly address object detection and tracking, presenting a Spatio-temporal bird’s eye view (BEV) feature map generation method and achieving robust tracking performance. ShaSTA [10] utilized Lidar sensors to learn shape and spatio-temporal affinities, effectively reducing false-positive and false-negative trajectories.
Recent developments include TrajectoryFormer [11], a novel 3D MOT framework combining long-term object motion and short-term appearance features for accurate estimation of hypotheses. 3DMOTFormer [12] builds upon the transformer architecture, employing an Edge-Augmented Graph Transformer for data association and achieving impressive results on benchmark datasets. These advancements underscore the growing potential of deep learning methods in enhancing the accuracy and efficiency of point cloud-based 3D MOT systems.
Experiments
What’s next?
References
[1] Zhang, P., Li, X., He, L., & Lin, X. (2023). 3D Multiple Object Tracking on Autonomous Driving: A Literature Review. https://arxiv.org/abs/2309.15411
[2] Weng, X., Wang, J., Held, D., & Kitani, K. (2020). 3D Multi-Object Tracking: A Baseline and New Evaluation Metrics. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 10359–10366. https://doi.org/10.1109/IROS45743.2020.9341164
[3] Weng, X., Yuan, Y., & Kitani, K. (2020). PTP: Parallelized Tracking and Prediction with Graph Neural Networks and Diversity Sampling. https://arxiv.org/abs/2003.07847
[4] Zaech, J.-N., Liniger, A., Dai, D., Danelljan, M., & van Gool, L. (2022). Learnable Online Graph Representations for 3D Multi-Object Tracking. IEEE Robotics and Automation Letters, 7(2), 5103–5110. https://doi.org/10.1109/LRA.2022.3145952
[5] Luo, C., Yang, X., & Yuille, A. (2021). Exploring Simple 3D Multi-Object Tracking for Autonomous Driving. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 10468–10477. https://doi.org/10.1109/ICCV48922.2021.01032
[6] Shen, Y., Wang, G., & Wang, H. (2022). DetFlowTrack: 3D Multi-object Tracking based on Simultaneous Optimization of Object Detection and Scene Flow Estimation. https://arxiv.org/abs/2203.02157
[7] Liu, J., Bai, L., Xia, Y., Huang, T., Zhu, B., & Han, Q.-L. (2023). GNN-PMB: A Simple but Effective Online 3D Multi-Object Tracker Without Bells and Whistles. IEEE Transactions on Intelligent Vehicles, 8(2), 1176–1189. https://doi.org/10.1109/TIV.2022.3217490
[8] Willes, J., Reading, C., & Waslander, S. L. (2023). InterTrack: Interaction Transformer for 3D Multi-Object Tracking. 2023 20th Conference on Robots and Vision (CRV), 73–80. https://doi.org/10.1109/CRV60082.2023.00017
[9] Gwak, J., Savarese, S., & Bohg, J. (2022). Minkowski Tracker: A Sparse Spatio-Temporal R-CNN for Joint Object Detection and Tracking. https://arxiv.org/abs/2208.10056
[10] Sadjadpour, T., Li, J., Ambrus, R., & Bohg, J. (2024). ShaSTA: Modeling Shape and Spatio-Temporal Affinities for 3D Multi-Object Tracking. IEEE Robotics and Automation Letters, 9(5), 4273–4280. https://doi.org/10.1109/LRA.2023.3323124
[11] Chen, X., Shi, S., Zhang, C., Zhu, B., Wang, Q., Cheung, K. C., See, S., & Li, H. (2023). TrajectoryFormer: 3D Object Tracking Transformer with Predictive Trajectory Hypotheses. https://arxiv.org/abs/2306.05888
[12] Ding, S., Rehder, E., Schneider, L., Cordts, M., & Gall, J. (2023). 3DMOTFormer: Graph Transformer for Online 3D Multi-Object Tracking. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 9750–9760. https://doi.org/10.1109/ICCV51070.2023.00897