End-to-End Perception - Experiments
In this blog post, we will talk about the concept of end-to-end perception, also known as joint perception and prediction, explore state-of-the-art methodologies across a taxonomy defined by me, discuss evaluation metrics tailored for these advanced systems, and share insights from my recent experiments in this research domain. Finally, I will outline the next steps in my PhD journey.
Definition of end-to-end perception
Traditional approaches to self-driving vehicles typically segment the perception problem into three distinct steps: object detection, object tracking, and motion prediction. In this cascade approach, the output of each stage serves as the input for the next. For instance, the detector identifies objects, whose locations are then tracked over time. These tracked trajectories are used to forecast future movements of traffic participants. While functional, this method treats each module independently, rarely propagating uncertainty from one stage to the next. This cascaded approach can lead to significant errors, as mistakes in early stages can accumulate and magnify, leading to potentially catastrophic failures downstream the perception pipeline.
In contrast, end-to-end perception offers a more integrated solution. This approach employs a single neural network—or several network architectures jointly optimized using a multi-task loss function—that performs simultaneous 3D detection, tracking (in some cases), and motion forecasting by leveraging spatio-temporal information captured by 3D sensors. By integrating these tasks into a single framework, end-to-end perception allows for more robust and efficient processing. Tracking and prediction, for instance, can enhance object detection by reducing false negatives in cases of occlusion or distant objects and decreasing false positives through temporal evidence accumulation. This holistic reasoning not only improves detection accuracy but also ensures better uncertainty propagation throughout the network, leading to more reliable estimates.
Moreover, end-to-end perception significantly boosts efficiency by sharing computations across tasks, which is crucial in the context of autonomous driving where low latency is essential for safety. This unified approach capitalizes on temporal information for improved motion forecasting and provides a more comprehensive understanding of the driving environment. By addressing the limitations of the traditional cascade approach, end-to-end perception represents a substantial advancement towards more reliable and effective autonomous driving systems.
State of the art
In the field of end-to-end perception for autonomous driving, the state-of-the-art methodologies can be categorized into three primary approaches: object-level, motion-level, and occupancy-level. These approaches are distinguished by the nature of their outputs. Object-level approaches use bounding boxes to represent objects, predicting their locations for the current frame and several frames into the future. Motion-level approaches, on the other hand, detect objects at the pixel level without bounding boxes, predicting the motion for all pixels that make up a single rigid object. Finally, occupancy-level approaches predict the occupancy grid map of the environment and the occupancy flow of cells that are moving in the scene. In the following sections, we will explore these three types of approaches, exploring their unique characteristics, advantages, and contributions to the advancement of the state of the art.
Agent-level approaches
Agent-level approaches in end-to-end perception for autonomous driving focus on detecting objects and predict its future trajectory using bounding boxes or waypoints. These methods typically take multiple frames from a 3D LiDAR sensor as input and utilize a multi-task neural network to output bounding boxes with orientation for both current and future frames.
The input data is often parametrized into a 2D bird’s-eye view (BEV) image by concatenating several sweeps of point clouds into a single image with ego-motion compensation. Each channel in this image can encode different features, such as height and time, allowing the network to leverage temporal and spatial information effectively. This representation facilitates the use of 2D convolutions, which can process the data efficiently by treating the height dimension as additional channels.
While the primary network performs detection and motion prediction, the tracking of objects is sometimes handled as a post-processing step rather than being integrated into the neural network itself. This separation can simplify the network architecture and allow specialized algorithms to refine the tracking based on the detection outputs.
The following research papers exemplify this approach:
- Camera input
- [arXiv 2022] Perceive, Interact, Predict: Learning Dynamic and Static Clues for End-to-End Motion Prediction [paper]
- [CVPR 2023] ViP3D: End-to-End Visual Trajectory Prediction via 3D Agent Queries [paper][Github]
- [ICCV 2023] VAD: Vectorized Scene Representation for Efficient Autonomous Driving [paper][Github]
- LiDAR input
- [CVPR 2018] Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net [paper]
- [CoRL 2018] IntentNet: Learning to Predict Intention from Raw Sensor Data [paper]
- [CVPR 2019] End-to-End Interpretable Neural Motion Planner [paper]
- [ICRA 2020] SpAGNN: Spatially-Aware Graph Neural Networks for Relational Behavior Forecasting from Sensor Data [paper]
- [CVPR 2020] PnPNet: End-to-End Perception and Prediction with Tracking in the Loop [paper]
- [CVPR 2020] STINet: Spatio-Temporal-Interactive Network for Pedestrian Detection and Trajectory Prediction [paper]
- [ECCV 2020] Implicit Latent Variable Model for Scene-Consistent Motion Forecasting [paper]
- [CoRL 2020] Inverting the Pose Forecasting Pipeline with SPF2: Sequential Pointcloud Forecasting for Sequential Pose Forecasting [paper][Github]
- [IROS 2020] The Importance of Prior Knowledge in Precise Multimodal Prediction [paper]
- [ACCV 2020] SDP-Net: Scene Flow Based Real-Time Object Detection and Prediction from Sequential 3D Point Clouds [paper]
- [IEEE RAL 2021] LaserFlow: Efficient and Probabilistic Object Detection and Motion Forecasting [paper]
- [CVPR 2021] Deep Multi-Task Learning for Joint Localization, Perception, and Prediction [paper]
- [ICCV 2021] LookOut: Diverse Multi-Future Prediction and Planning for Self-Driving [paper]
- [IEEE IV 2021] MultiXNet: Multiclass Multistage Multimodal Motion Prediction [paper]
- [IEEE IJCNN 2021] SDAPNet: End-to-End Multi-task Simultaneous Detection and Prediction Network [paper]
- [CVPRW 2021] MVFuseNet: Improving End-to-End Object Detection and Motion Forecasting through Multi-View Fusion of LiDAR Data [paper]
- [IROS 2021] RV-FuseNet: Range View Based Fusion of Time-Series LiDAR Data for Joint 3D Object Detection and Motion Forecasting [paper]
- [CVPR 2022] Forecasting from LiDAR via Future Object Detection [paper][Github]
- [ITSC 2022] FS-GRU: Continuous Perception and Prediction with inter Frame Feature Sharing [paper]
- [ECCV 2024] DeTra: A Unified Model for Object Detection and Trajectory Forecasting [paper][website]
- Multi-modal input
- [IROS 2020] End-to-end Contextual Perception and Prediction with Interaction Transformer [paper]
- [CoRL 2020] LiRaNet: End-to-End Trajectory Prediction using Spatio-Temporal Radar Fusion [paper]
- [WACV 2022] Multi-View Fusion of Sensor Data for Improved Perception and Prediction in Autonomous Driving [paper]
 Figure 1: Fast and Furious qualitative results. [1]
Figure 1: Fast and Furious qualitative results. [1]
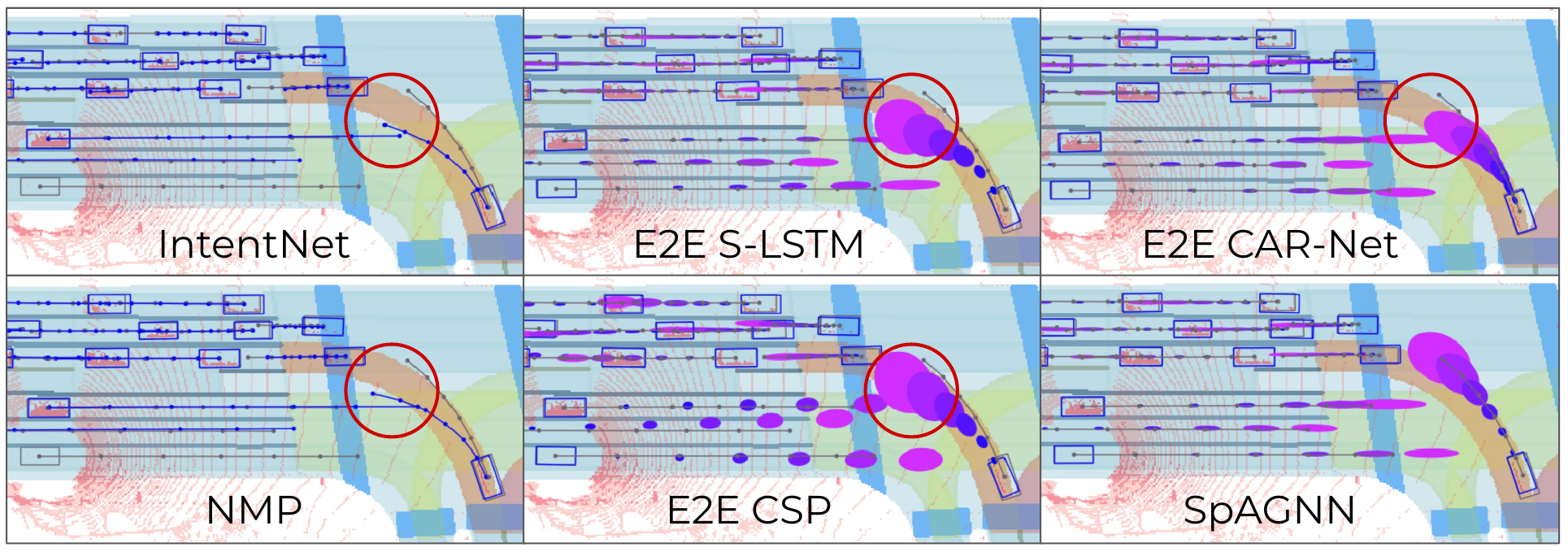 Figure 2: SpAGNN qualitative results. [2]
Figure 2: SpAGNN qualitative results. [2]
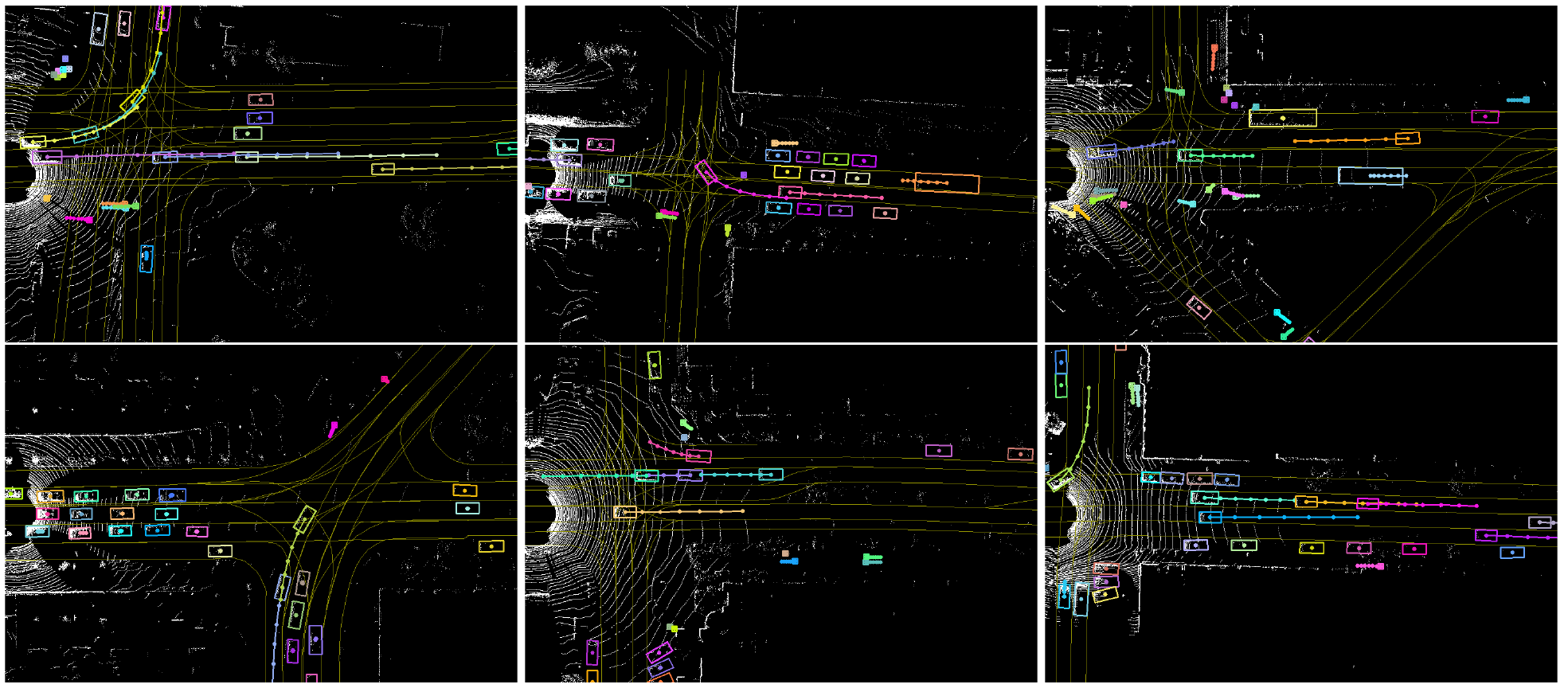 Figure 3: PnPNet qualitative results. [3]
Figure 3: PnPNet qualitative results. [3]
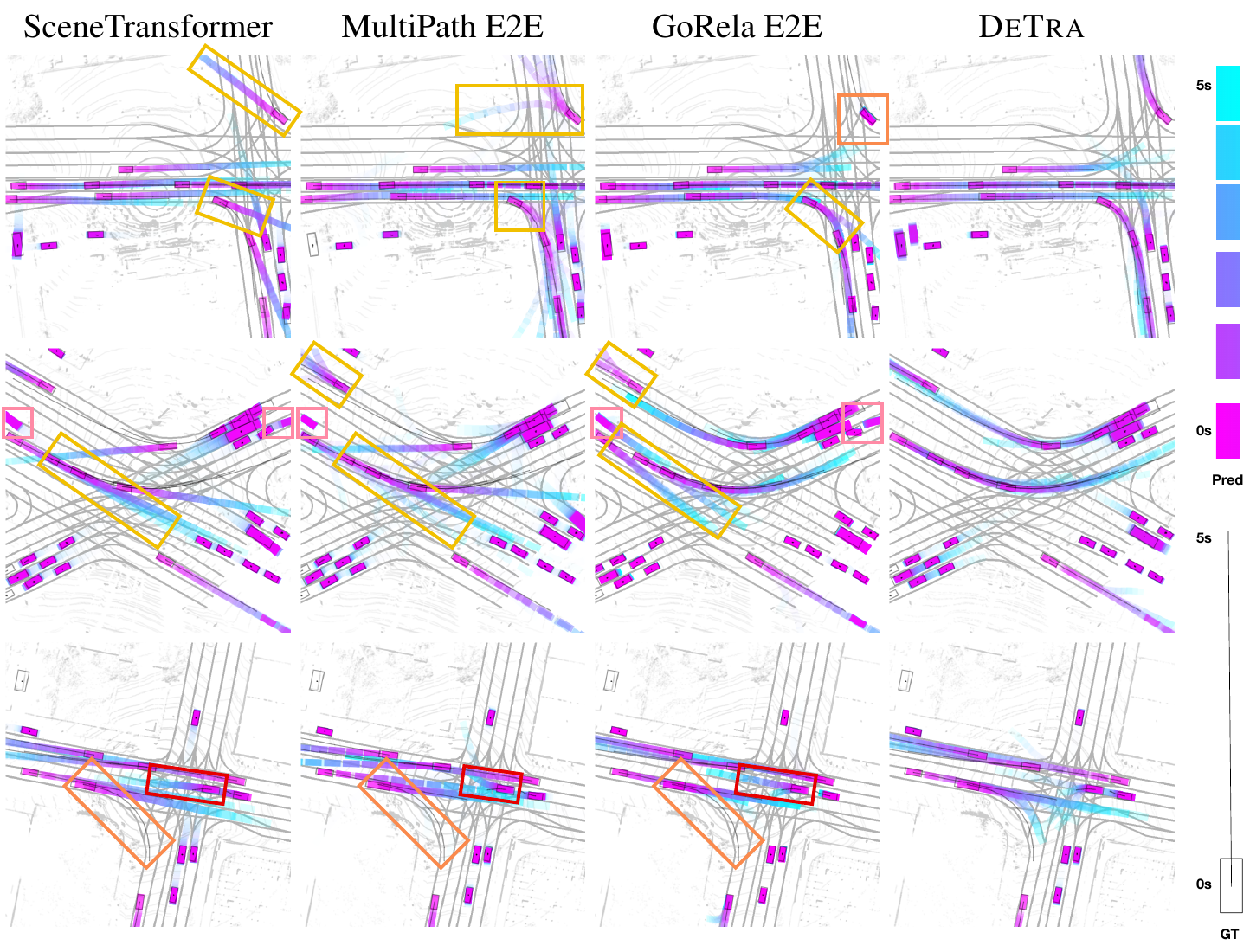 Figure 4: DeTra qualitative results. [4]
Figure 4: DeTra qualitative results. [4]
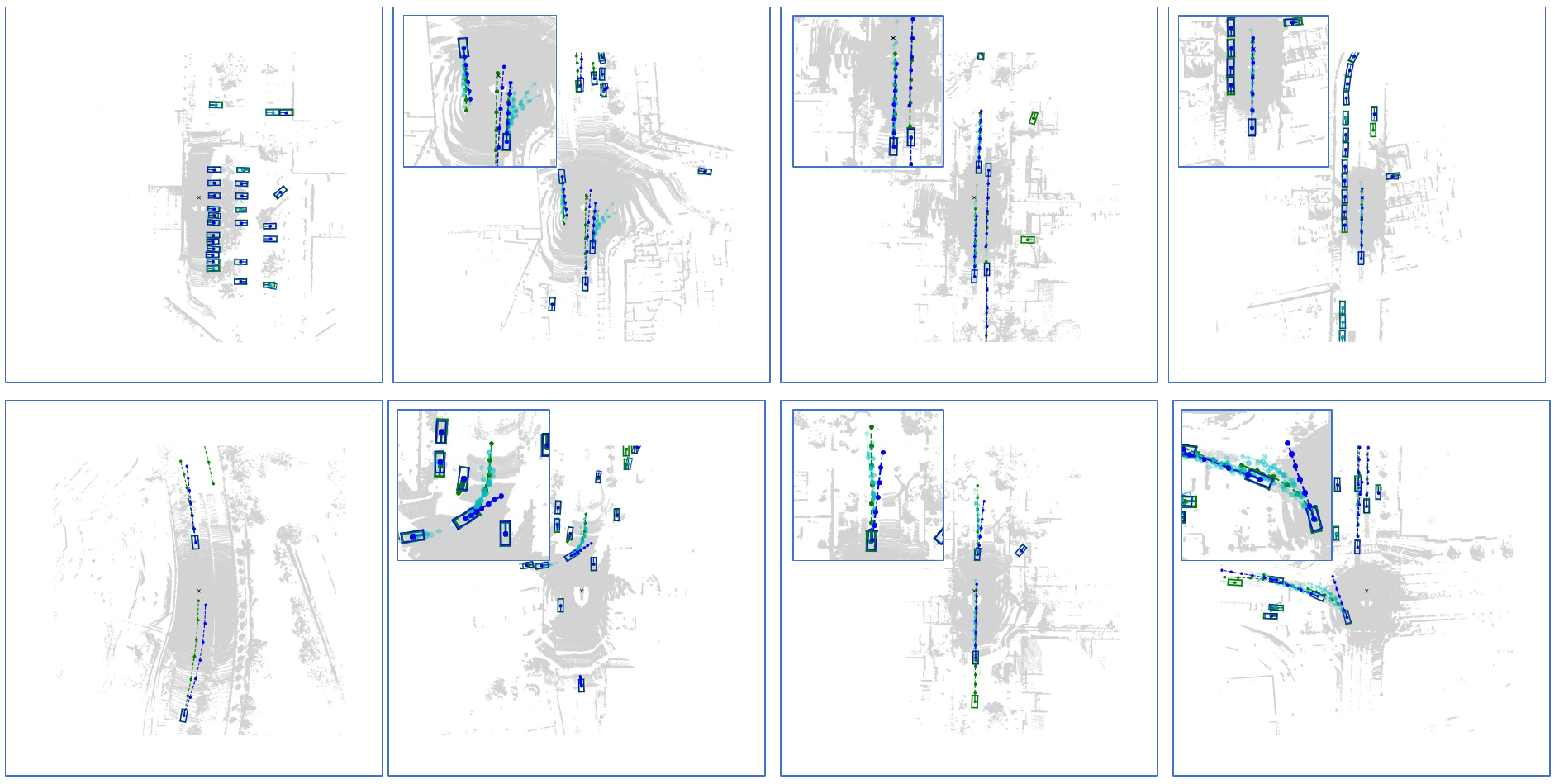 Figure 5: FutureDet qualitative results. [5]
Figure 5: FutureDet qualitative results. [5]
Motion-level approaches
Motion-level approaches in end-to-end perception for autonomous driving represent a shift from traditional bounding box-based methods. These approaches focus on detecting objects and predicting their motion at the pixel level, without relying on predefined bounding boxes. This pixel-level representation enables more detailed and flexible perception and prediction, especially in complex and dynamic driving environments.
These methods typically use a bird’s-eye view (BEV) map derived from 3D LiDAR data. The point cloud data is discretized into a grid of cells, with each cell containing information about its occupancy, motion, and category. This BEV map not only provides a spatial representation of the environment but also encodes the motion information through displacement vectors, which represent the positions of the cells into the future. This allows for the modeling of nonlinear dynamics and offers a comprehensive view of the motion behavior of individual objects.
A significant advantage of motion-level approaches is their ability to handle open-set scenarios, where objects that have not been seen during training may appear. By predicting motion at the pixel level, these approaches can recognize and track objects based on their motion patterns, even if their specific class was not part of the training data. This flexibility enhances the robustness of the perception system in real-world traffic scenarios.
The following research papers exemplify this approach:
- LiDAR input
- [CVPR 2020] MotionNet: Joint Perception and Motion Prediction for Autonomous Driving based on BEV Maps [paper][Github]
- [IEEE VTC-Fall 2021] End-to-End Multi-View Fusion for Enhanced Perception and Motion Prediction [paper]
- [IEEE IV 2022] Spatiotemporal Transformer Attention Network for 3D Voxel Level Joint Segmentation and Motion Prediction in Point Cloud [paper]
- [CVPR 2022] BE-STI: Spatial-Temporal Integrated Network for Class-Agnostic Motion Prediction with Bidirectional Enhancement [paper]
- [GLOBECOM 2022] LidNet: Boosting Perception and Motion Prediction from a Sequence of LIDAR Point Clouds for Autonomous Driving [paper]
- [CVPR 2023] Weakly Supervised Class-Agnostic Motion Prediction for Autonomous Driving [paper][Github]
- [IJCAI 2023] ContrastMotion: Self-supervised Scene Motion Learning for Large-Scale LiDAR Point Clouds [paper]
- [AAAI 2024] Semi-Supervised Class-Agnostic Motion Prediction with Pseudo Label Regeneration and BEVMix [paper][Github]
- [CVPR 2024] Self-Supervised Class-Agnostic Motion Prediction with Spatial and Temporal Consistency Regularizations [paper][Github]
- Multi-modal input
- [IEEE Access 2021] LiCaNext: Incorporating Sequential Range Residuals for Additional Advancement in Joint Perception and Motion Prediction [paper]
- [CVPR 2021] Self-Supervised Pillar Motion Learning for Autonomous Driving [paper][Github]
- [IEEE OJITS 2022] LiCaNet: Further Enhancement of Joint Perception and Motion Prediction Based on Multi-Modal Fusion [paper]
- [AAAI 2024] Self-Supervised Bird’s Eye View Motion Prediction with Cross-Modality Signals [paper][Github]
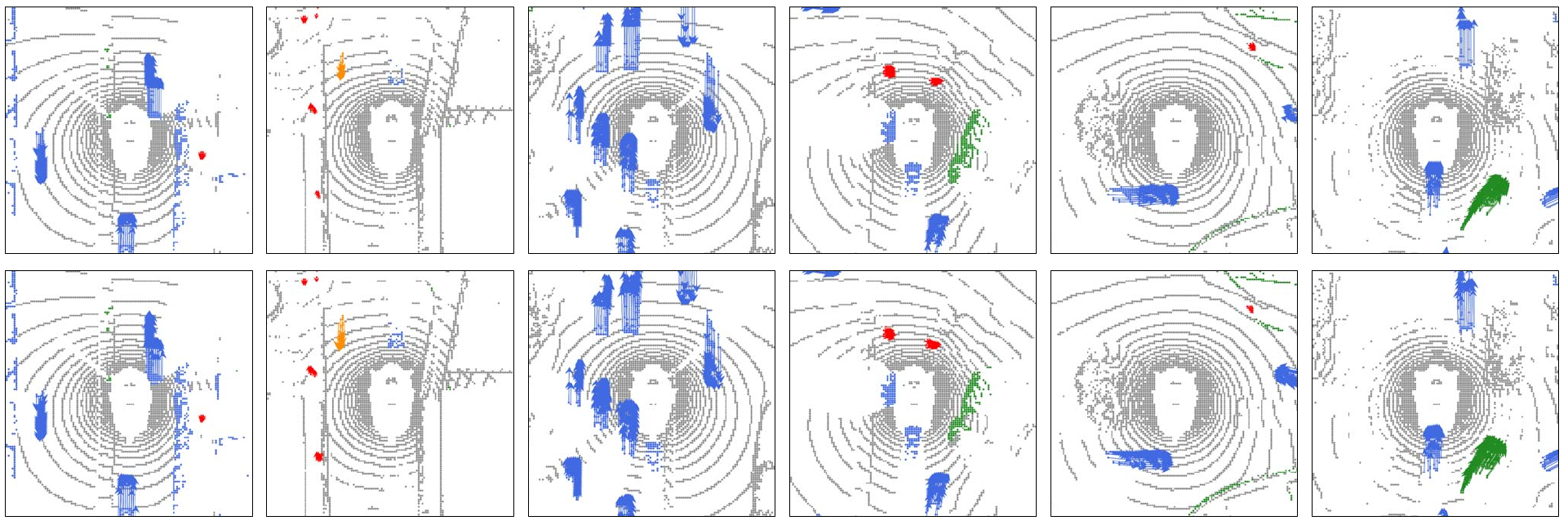 Figure 6: MotionNet qualitative results. [6] Top row: ground-truth. Bottom: MotionNet predictions. Gray: background; blue: vehicle; red: pedestrian; orange: bicycle; green: others.
Figure 6: MotionNet qualitative results. [6] Top row: ground-truth. Bottom: MotionNet predictions. Gray: background; blue: vehicle; red: pedestrian; orange: bicycle; green: others.
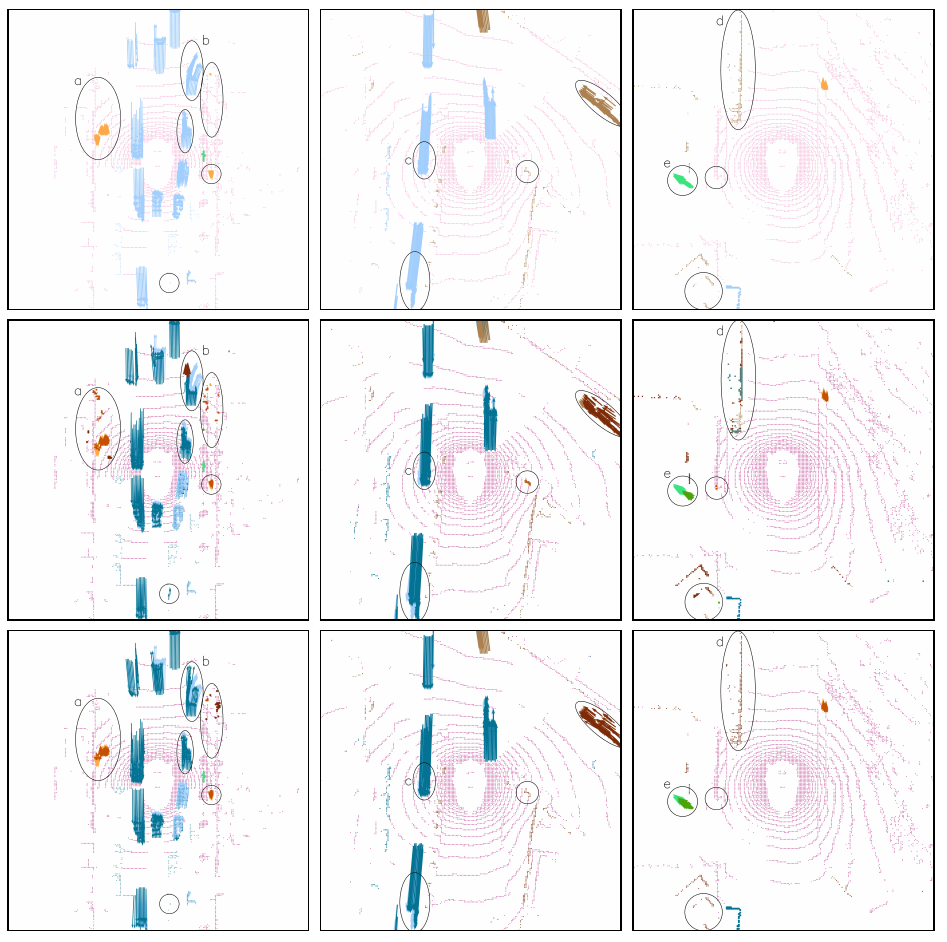 Figure 7: LidNet qualitative results. [7] Top row: ground truth. Middle row: MotionNet. Bottom row: LidNet. Ground truth is also present in the second and third row for easier visual comparison. Background pink — Vehicle blue — Pedestrian orange — Bike green — Other brown.
Figure 7: LidNet qualitative results. [7] Top row: ground truth. Middle row: MotionNet. Bottom row: LidNet. Ground truth is also present in the second and third row for easier visual comparison. Background pink — Vehicle blue — Pedestrian orange — Bike green — Other brown.
Occupancy-level approaches
Occupancy-level approaches in end-to-end perception for autonomous driving represent an evolution beyond traditional object-based methods. Instead of detecting individual objects, these methods focus on predicting the occupancy probability and motion for every cell in a spatio-temporal grid directly from sensor data. This approach eliminates the need for confidence thresholding and can provide a more expressive distribution over future motions, enhancing the ability of the system to plan for low-probability objects and events.
In an occupancy-level approach, the environment is represented as a 3D dense grid with two spatial dimensions (forming a bird’s-eye view) and a temporal dimension extending from the current observation to a future horizon. Each cell in this grid is quantized at regular intervals and holds information about whether it is occupied (occupancy grid map) and how its occupancy is likely to change over time (occupancy flow). This method provides a comprehensive view of both static and dynamic elements in the scene.
One of the key advantages of occupancy-level approaches is their ability to handle the full distribution of possible futures for all elements in the scene. This is particularly important in ensuring safety, as it avoids the information loss associated with thresholding detection scores in object-based models. Consequently, it allows for a more robust handling of scenarios where objects might be below the detection threshold or where future behaviors are complex and not easily captured by simple trajectory estimates.
However, these approaches are computationally intensive due to the high dimensionality of the grid required to minimize quantization errors. To address this, researchers focus on optimizing computational and memory resources, ensuring that the motion planner considers only relevant spatio-temporal points rather than a dense region of interest.
By predicting occupancy grids and their evolution over time, occupancy-level methods enable more reliable and interpretable intermediate representations. These representations are crucial for understanding the reasons behind the vehicle’s maneuvers, which is vital for safety-critical applications such as self-driving cars. This holistic perception of the environment allows autonomous vehicles to navigate complex and dynamic environments, such as urban areas, with greater safety and efficiency.
The following research papers exemplify this approach:
- Camera input
- [ICCV 2021] FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras [paper][Github]
- [ECCV 2022] StretchBEV: Stretching Future Instance Prediction Spatially and Temporally [paper][Github]
- [arXiv 2022] BEVerse: Unified Perception and Prediction in Birds- Eye-View for Vision-Centric Autonomous Driving [paper][Github]
- [ECCV 2022] ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning [paper][Github]
- [IJCAI 2023] PowerBEV: A Powerful Yet Lightweight Framework for Instance Prediction in Bird’s-Eye View [paper][Github]
- [CVPR 2023] TBP-Former: Learning Temporal Bird’s-Eye-View Pyramid for Joint Perception and Prediction in Vision-Centric Autonomous Driving [paper][Github]
- [arXiv 2023] Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Applications [paper][Github]
- LiDAR input
- [ECCV 2020] Perceive, Predict, and Plan: Safe Motion Planning Through Interpretable Semantic Representations [paper]
- [CVPR 2021] MP3: A Unified Model to Map, Perceive, Predict and Plan [paper]
- [ECCV 2022] Differentiable Raycasting for Self-Supervised Occupancy Forecasting [paper][Github]
- [CVPR 2023] Point Cloud Forecasting as a Proxy for 4D Occupancy Forecasting [paper][Github]
- [CVPR 2023] Implicit Occupancy Flow Fields for Perception and Prediction in Self-Driving [paper][website]
- [arXiv 2023] LiDAR-based 4D Occupancy Completion and Forecasting [paper][Github]
- Multi-modal input
- [CVPRW 2020] FISHING Net: Future Inference of Semantic Heatmaps in Grids [paper]
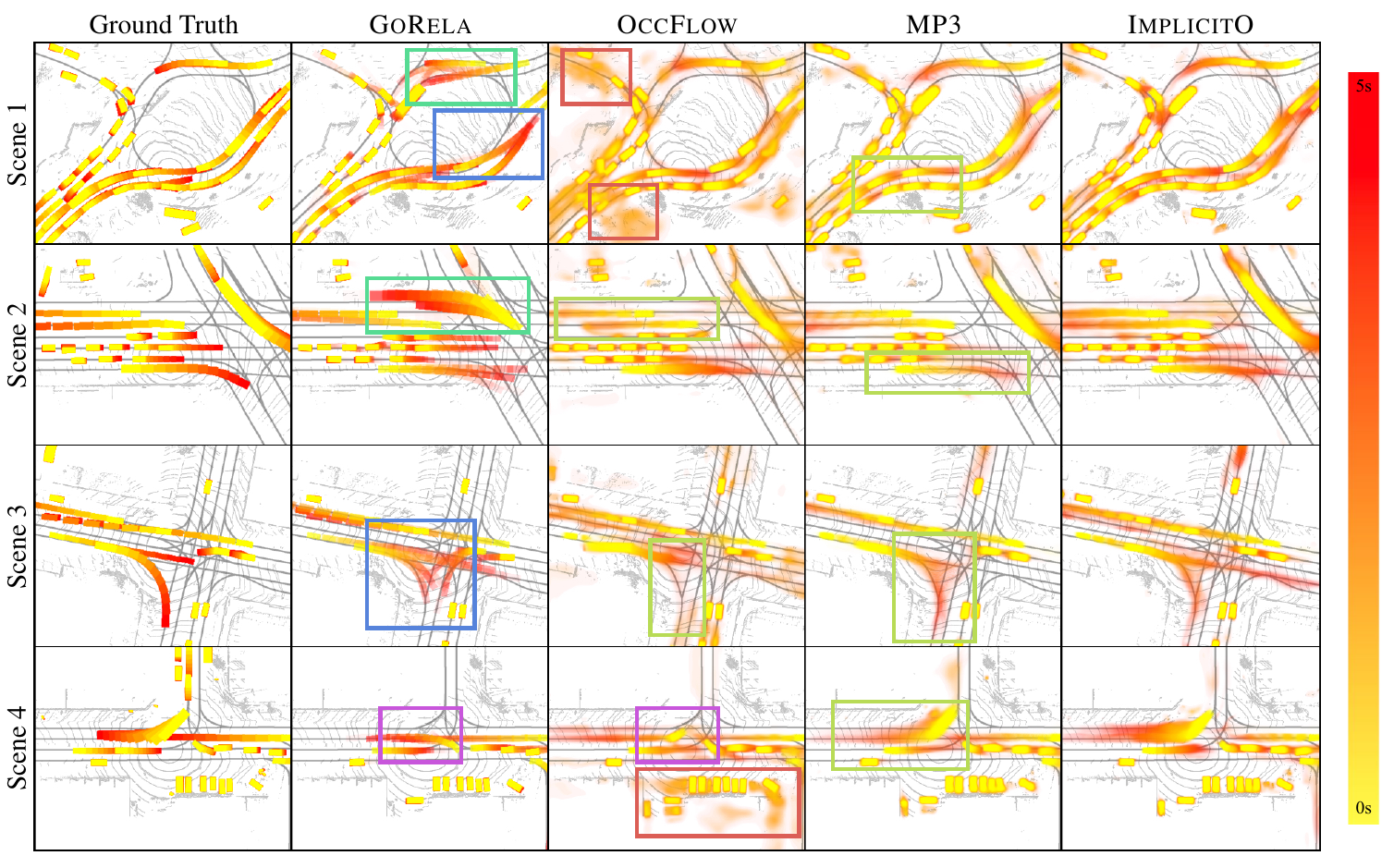 Figure 8: ImplicitO qualitative results. [8].
Figure 8: ImplicitO qualitative results. [8].
Others (Agent-level + Occupancy-level)
- Camera input
- LiDAR input
- [IROS 2021] Safety-Oriented Pedestrian Motion and Scene Occupancy Forecasting [paper]
- Multi-modal input
Evaluation metrics
Evaluating end-to-end perception approaches for autonomous driving involves measuring the performance of multiple interconnected tasks. To accurately assess these systems, two main families of metrics are used: independent metrics for each perception task and joint metrics for end-to-end perception. Independent metrics evaluate the performance of individual components like detection, tracking, and prediction, while joint metrics assess the overall effectiveness and coherence of the integrated end-to-end perception system. This dual approach ensures a comprehensive evaluation of both individual task proficiency and the synergy between tasks within the end-to-end framework.
Independent metrics for each perception task
In evaluating end-to-end perception systems for autonomous driving, it’s crucial to assess the performance of each individual perception task using specific metrics tailored to those tasks.
- Object Detection Metrics
- Mean Average Precision (mAP): This is the most commonly used metric for evaluating object detection. It measures the average precision across all classes and is calculated by plotting the precision-recall curve for each class and finding the area under the curve.
- Intersection over Union (IoU): Often used in conjunction with mAP, IoU measures the overlap between the predicted bounding box and the ground truth bounding box.
- Object Tracking Metrics
- Average Multi-Object Tracking Accuracy (AMOTA): This metric evaluates the accuracy of tracking over multiple objects and is an averaged version of MOTA across different recall thresholds.
- Average Multi-Object Tracking Precision (AMOTP): This metric measures the precision of tracking by averaging the positional errors of matched object pairs over different recall thresholds.
- Multi-Object Tracking Accuracy (MOTA): A comprehensive metric that accounts for false positives, missed targets, and identity switches.
- Multi-Object Tracking Precision (MOTP): This metric evaluates the precision of the predicted object locations by measuring the average distance between predicted and ground truth object locations.
- Motion Prediction Metrics
- Average Displacement Error (ADE): Measures the average distance between the predicted trajectory and the ground truth trajectory over all time steps.
- Final Displacement Error (FDE): Measures the distance between the predicted endpoint of the trajectory and the ground truth endpoint.
- Miss Rate: Evaluates the frequency with which predicted trajectories miss the ground truth trajectory by a certain threshold.
These independent metrics ensure that each component of the end-to-end perception system is performing optimally before assessing the system’s overall integrated performance.
Joint metrics for end-to-end perception
Evaluating end-to-end perception systems requires more than just the independent assessment of object detection, object tracking, and motion prediction tasks. Traditional metrics for these tasks often fall short in capturing the intertwined nature of these processes. As a result, the industry has moved towards joint metrics, which evaluate the combined performance of detection and forecasting, providing a more comprehensive understanding of a system’s capabilities.
Disadvantages of Independent Metrics
Independent metrics like Average Displacement Error (ADE) and Final Displacement Error (FDE) are commonly used to assess trajectory prediction. ADE measures the average L2 distance between predicted and ground truth trajectories, while FDE measures the L2 distance at the final prediction time. These metrics are effective in isolated scenarios but assume a consistent set of true positives across different methods, which isn’t practical in end-to-end systems where detection influences forecasting accuracy.
Miss Rate, another independent metric, evaluates the proportion of forecasts exceeding a predefined error threshold. While useful, it focuses only on matched detections and neglects false positives, allowing models to produce numerous unanchored forecasts without penalty.
ADE/FDE with recall thresholds (e.g., 60% or 90%) have been proposed to account for detection accuracy. However, these too can be gamed by models that prioritize stationary objects, leading to artificially high scores without truly robust predictions.
These independent metrics don’t fully address the interconnected nature of detection and forecasting, often leading to incomplete or misleading evaluations. In other words, this approach does not penalize false forecasts, i.e., forecasts not anchored to any detection, and missed forecasts as commonly characterized by the miss rate.
Introduction of Joint Metrics
To overcome these limitations, joint metrics were developed to evaluate detection and forecasting in tandem. One such metric is Average Precision (AP), traditionally used for object detection. AP measures the area under the precision-recall curve, providing a single score that balances precision (the accuracy of the detections) and recall (the ability to find all relevant instances).
For end-to-end tasks, this concept is extended to Forecasting Average Precision (APf). APf evaluates both the current detection accuracy and the quality of future trajectory forecasts. This metric considers a prediction successful only if it matches the ground truth in both the current frame and the future frame, ensuring that both detection and forecasting are accurate.
Forecasting Average Precision (APf)
APf is designed to address the shortcomings of independent metrics by integrating detection and forecasting evaluations. Here’s how it works:
- Current Frame Accuracy: A prediction must match the ground truth object in the current frame based on a defined distance threshold. This ensures the detection part of the task is accurate.
- Future Frame Accuracy: The same prediction must also match the future position of the object at a specified future time. This ensures the forecasting part of the task is accurate.
APf considers a forecast as a true positive only if it meets both criteria. This dual requirement effectively penalizes models for false detections and inaccurate forecasts, providing a more holistic evaluation of the system’s performance.
Forecasting Mean Average Precision (mAPf)
To further refine the evaluation, Forecasting Mean Average Precision (mAPf) is introduced. This metric addresses data imbalance by evaluating performance across different object motion categories:
- Static Objects: Objects that remain stationary, which are easier to predict.
- Linearly Moving Objects: Objects that move in predictable, straight-line paths.
- Non-Linearly Moving Objects: Objects that move in complex, unpredictable ways.
By averaging APf across these sub-categories, mAPf ensures that the evaluation cannot be gamed by models focusing only on easier predictions, like stationary objects. This nuanced metric provides insights into how well the model handles different types of motion, which is crucial for real-world applications.
Embracing Multiple Futures
In practical scenarios, especially in dynamic environments, there can be multiple plausible future trajectories for objects. Joint metrics account for this by using a top-K evaluation approach, where the best K predictions are considered for each detected object. This method avoids penalizing models for hypothesizing multiple potential futures, allowing for a more realistic assessment of predictive capabilities.
Experiments
What’s next?
References
[1] Luo, W., Yang, B., & Urtasun, R. (2018). Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3569–3577. https://doi.org/10.1109/CVPR.2018.00376
[2] Casas, S., Gulino, C., Liao, R., & Urtasun, R. (2020). SpAGNN: Spatially-Aware Graph Neural Networks for Relational Behavior Forecasting from Sensor Data. 2020 IEEE International Conference on Robotics and Automation (ICRA), 9491–9497. https://doi.org/10.1109/ICRA40945.2020.9196697
[3] Liang, M., Yang, B., Zeng, W., Chen, Y., Hu, R., Casas, S., & Urtasun, R. (2020). PnPNet: End-to-End Perception and Prediction With Tracking in the Loop. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11550–11559. https://doi.org/10.1109/CVPR42600.2020.01157
[4] Casas, S., Agro, B., Mao, J., Gilles, T., Cui, A., Li, T., & Urtasun, R. (2024). DeTra: A Unified Model for Object Detection and Trajectory Forecasting. https://arxiv.org/abs/2406.04426
[5] Peri, N., Luiten, J., Li, M., Osep, A., Leal-Taixe, L., & Ramanan, D. (2022). Forecasting from LiDAR via Future Object Detection. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 17181–17190. https://doi.org/10.1109/CVPR52688.2022.01669
[6] Wu, P., Chen, S., & Metaxas, Di. N. (2020). MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird’s Eye View Maps. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11382–11392. https://doi.org/10.1109/CVPR42600.2020.01140
[7] Khalil, Y. H., & Mouftah, H. T. (2022). LidNet: Boosting Perception and Motion Prediction from a Sequence of LIDAR Point Clouds for Autonomous Driving. GLOBECOM 2022 - 2022 IEEE Global Communications Conference, 3533–3538. https://doi.org/10.1109/GLOBECOM48099.2022.10001152
[8] Agro, B., Sykora, Q., Casas, S., & Urtasun, R. (2023). Implicit Occupancy Flow Fields for Perception and Prediction in Self-Driving. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1379–1388. https://doi.org/10.1109/CVPR52729.2023.00139